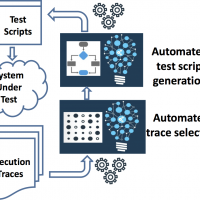
This section details the four research objectives of the PHILAE project and the related scientific challenges and technical barriers to be solved.
Objective 1 – Select trace candidate as new regression tests
This objective is to take the large set of User Execution Traces (from release N-1), plus the smaller set of Manual Testing Execution Traces (from release N), then compare, cluster, and prioritize them, in order to select a representative sample of the traces that can be used as the basis for learning new Workflow models for Release N, and as a basis for generating tests for Release N. Where available, an additional input into this selection process will be metadata about Release N code changes, so that recently changed areas can be prioritized.
Scientific challenges and technical barriers to be solved: one challenge in this objective is how to learn and select for rare events, because although our training data will have many traces from Release N-1 and only a few from Release N, we nevertheless wish to give high priority to 'rare' or 'unique' events that are new in Release N. Some research has been done on this area with deep neural nets [Kaiser17], but we will have to find pragmatic techniques that ensure that Release N behaviours are prioritized and learnt.
Objective 2 – Abstract workflows from traces
This objective will raise the level of abstraction of system traces by automatically classifying them and extracting high-level business workflows. This is related to existing work on learning abstractions, and on automatic model inference, but can be simplified in our situation because it is sufficient to infer a set of partial models (Workflows) for various scenarios, rather than one comprehensive behavioral model. These partial models are useful as a basis for automated test generation to produce reduced automated test suites, and for presenting partial views of system behavior. Moreover, points where an inferred workflow has changed between Release N-1 and Release N will be used as triggers to generate additional tests that provide more systematic testing than done by exploratory testing or user interactions. Note that for some inferred workflows it may be possible to generate test sequences that include oracle information (expected output values), but for other workflows it may only be possible to generate generic oracles such as 'no-exceptions thrown' or 'web-service returns a status message'. Our test execution framework will handle both kinds of test sequences.
Scientific challenges and technical barriers to be solved: the main challenges in this objective are: combining the various abstraction algorithms that are already available (e.g. clustering, abstraction-learning, and model-inference), and ensuring that the resulting workflows are not too abstract, so that they can still be used to generate feasible test sequences; and that they are easily understandable to be put in the context of the process.
Objective 3 – Automated regression test generation and execution
This objective will apply model-based test generation techniques to the inferred workflows to generate executable robustness tests and regression tests. It will generate robustness tests from the learned knowledge about data frequencies and data correlations, as well as any provided meta-information about data types and ranges. It will also use active learning and reinforcement learning techniques to expand the generated test suite to test the system more thoroughly. The generated tests will be executed on the new Release N of the system, thus creating a larger set of input traces that can be fed back into Step 1 in order to further refine the learned models of the system. This iterative process will produce a strong set of regression tests that can be used to test successive releases of the SUT (System Under Test), with minimal human effort.
Scientific challenges and technical barriers to be solved: It is easy to generate too many tests, so the main challenge here is prioritizing tests and minimizing the whole generated regression suite so that it has acceptable execution time.
Objective 4 – User-Friendly Fault Reporting
Anomaly detection is an important topic in this context, so providing smart analytics of test execution results is crucial to help test engineers focus on the more error-prone parts of the SUT. This objective will apply unsupervised machine learning algorithms based on clustering (hierarchical or flat clustering depending on the nature of the distance function being selected) to group test failures, and sort them depending on their priority level. It will also develop intelligent visualization of test results so that test failures can be visualized overlaid on concise and high-level business workflows. This will involve prioritizing the anomalies, abstraction of elements coming from the test failures, as well as applying trace minimization and abstraction tools. This will be enhanced with learning techniques based on associative networks that propagate dependencies to assess the relevance of pieces of information. This will enable test engineers and business analysts to see visually and textually where the SUT is failing, so understand which errors have priority or impact other errors.
Scientific challenges and technical barriers to be solved: we will have a range of different kinds of users who want to use this fault reporting system, so no one view will suit them all. We envisage providing alternative views, and some configuration features, to ameliorate this. But an iterative design process with regular feedback from different kinds of users will be important to ensure that the visualization system is usable and useful.
[Kaiser17] Łukasz Kaiser, Ofir Nachum, Aurko Roy and Samy Bengio, "Learning to Remember Rare Events", ICLR 2017. https://research.google.com/pubs/pub45801.html